Support Vector Machine
See also Support Vector Machine
- Classification
- Supervised
- Non-parametric
Support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis.
Hard-Margin SVM
Assumption: linear separable
Given
Derivation (distance from a point to a hyperplane)
See also SVM>Margin

Hence the max-min classifier that maximizes the margin (hard margin) is given by
Because linear separable, we can find
We can fix the scale of
Therefore it is equivalent to solve the following optimization problem:
- Is strictly convex
- If a solution exists, then it is unique
- Since we assume the data to be linearly separable, then a solution exists
This is also known as Max-Margin Classifier
Soft-Margin SVM
If the data is not linearly separable, we introduce some relaxation through slack variable
means false classification is the minimum amount of translation needed to make the optimization problem feasible is a hyper-parameter and

When we allow misclassifications, the distance between the observations and the threshold is the soft margin. Observations on the edge and within the the soft margin are support vectors.
- If
, is correctly classified (beyond margin) - If
, is correctly classified (within margin) - If
, is wrongly classified
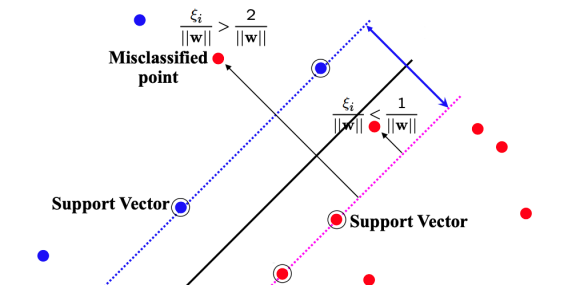
Also known as Support Vector Classifier
Support Vector Machine
Support Vector Machine is Hinge Loss with L2 Regularization
- The loss function is a penalty between a model and the truth
- Regularization is a penalty for too complex model
See also Neural Net#Overfitting
Hinge Loss
where
Derivation:
Further transformation into an unconstrained optimization problem
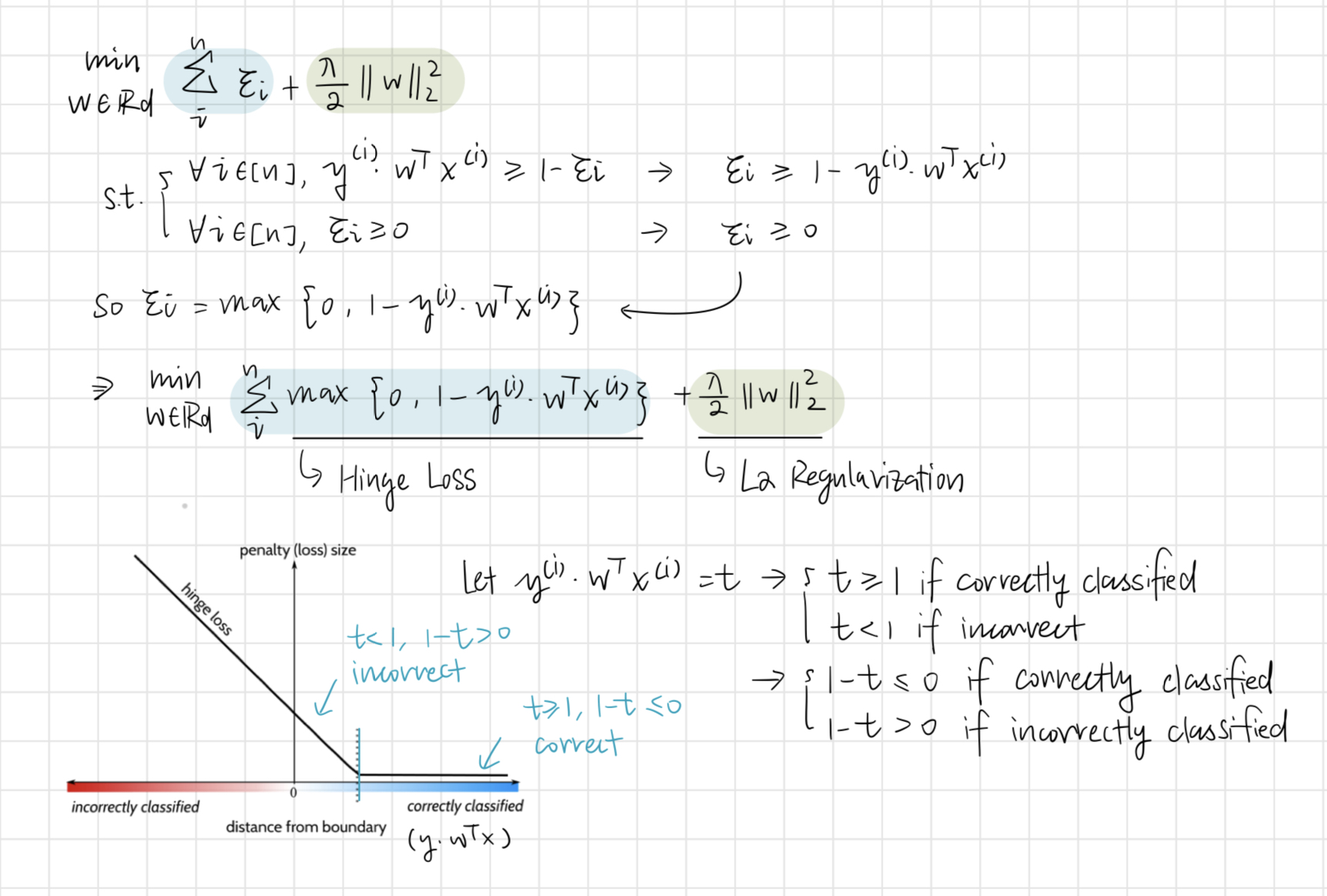
The hyper-parameter
- If
, then less focus on regularization, more focus on loss - If
, then more focus on regularization, less focus on loss
Dual SVM
In Hard-Margin SVM:
We introduce
(the Lagrangian)
- the price to pay if the corresponding constraint is violated - Transform into unconstrained problem
- Two cases (because we are trying to find
to maximize the equation): - If
th constraint holds, then - If
th constraint is violated, then
- If
- Primal Problem
- Dual Problem
This is because of Strong Duality:
- In general, for an arbitrary function
, we have weak duality
- For convex problems with affine constraints, we have strong duality
The Dual Problem
The dual problem
where
- The optimization
wrt is a quadratic program - Solve for
- Recover the optimal
with - The optimal normal vector
is a linear combination of - Only the ones with
contributes to - The ones with
does not contribute to - The points
with are support vectors
- The optimal normal vector
Dual solutions and support vectors are not necessarily unique
(even if the primal solution is unique)
Derivation:

The Dual Problem makes #Kernel Method easier
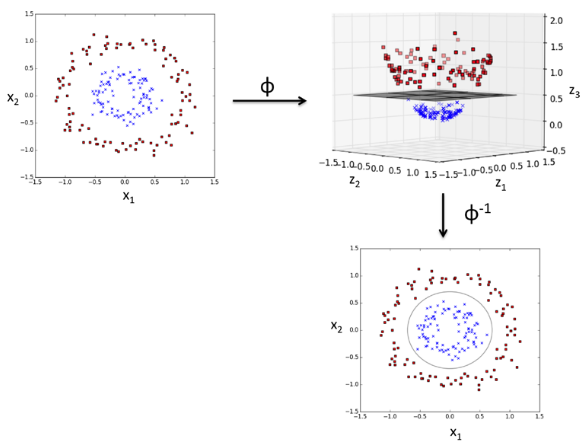
Kernel Method
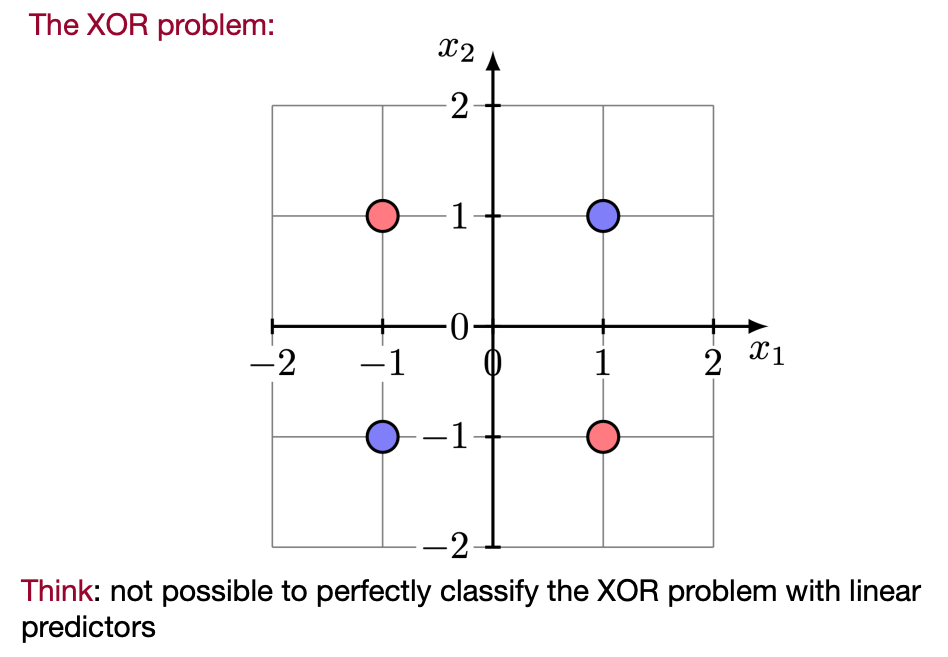
Sometimes datasets are linearly inseparable, in which case we use the Kernel Method.
Key idea is feature mapping/lifting to construct new features.
Example:
In the XOR Problem, we can add a third dimension
where
The primal optimization becomes
#The Dual Problem under the feature map
where
- The dual form never needs
explicitly, but only the inner product - Kernel Trick: Replace every
with kernel evaluation - Sometimes
is much cheaper - But we need to explicitly maintain
- Sometimes
Example:
Affine featureswith
The kernel form isQuadratic features
with
The kernel form is
RBF Kernel
Radial Basis Function (RBF/Gaussian) Kernel
For any