Distributed Datastores
Distributed NoSQL key-value stores
(e.g. MongoDB, DynamoDB by Amazon, Cassandra by Facebook)
CAP Theorem
In a distributed system you can only guarantee at most 2 out of the following 3 properties:
- Consistency: reads return latest written value by any client (all nodes see same data at any time)
- Availability: every request received by a non-failing node in the system must result in a response (quickly)
- Partition Tolerance: the system continues to work in spite of network partitions
We usually want to keep Partition Tolerance always
Cassandra
A distributed key-value store, intended to run in a datacenter, first designed by Facebook, now is an Apache project
Data Partitioning
Cassandra uses a ring-based Distributed Hash Table (DHT) but without finger or routing tables.
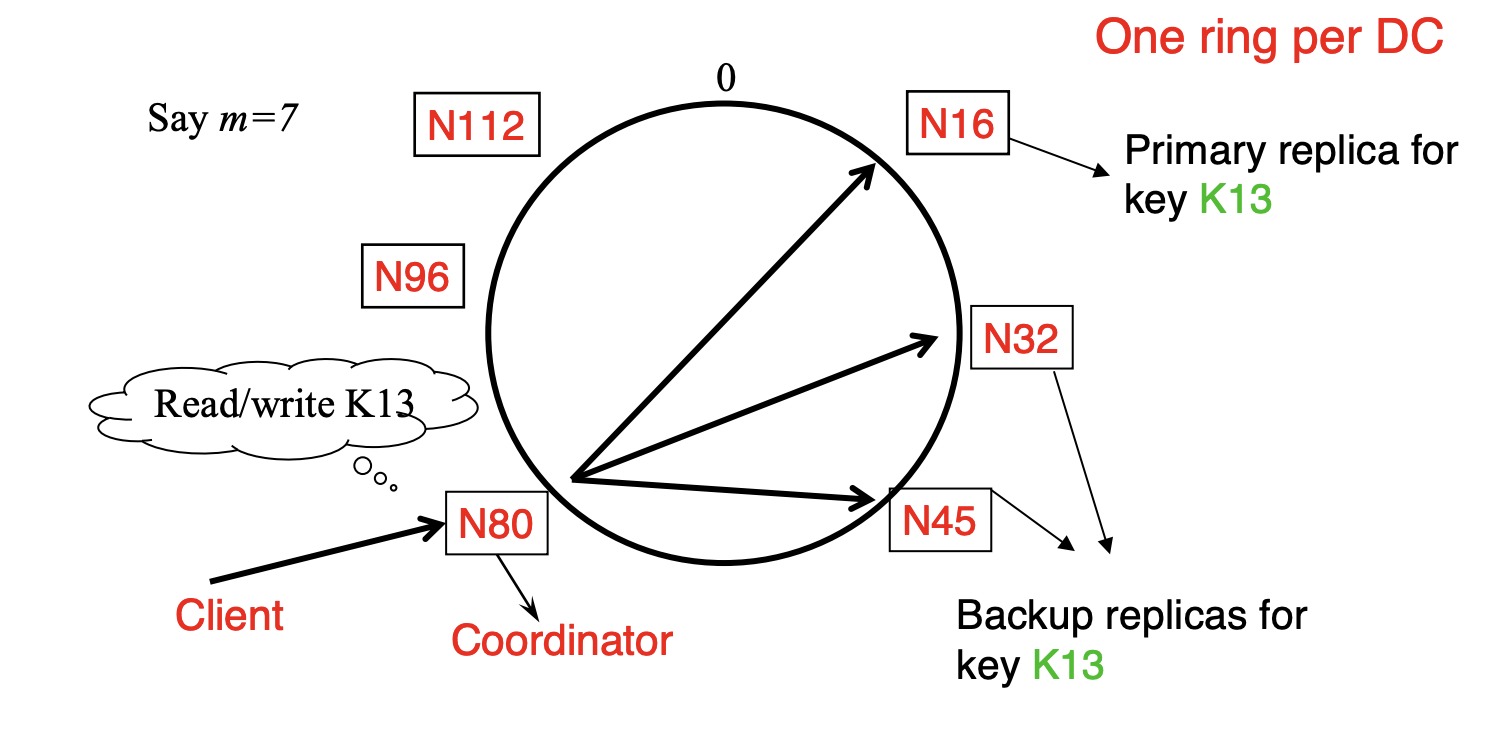
Partitioner
Partitioner is the component responsible for key to server mapping and determining the primary replica for a key. There are two types:
- Chord-like hash partitioning: uses a hash function
- Byte-ordered Partitioner: assigns ranges of keys to servers
- Easier for range queries
Replication Policies
Two options for replication strategy:
- Simple Strategy:
- First replica placed based on the partitioner
- Remaining replicas clockwise in relation to the primary replica
- Network Topology Strategy:
- Two or three replicas per data center
- Per data center
- First replica placed according to Partitioner
- Then go clockwise around ring until you hit a different rack
Operations
Writes
- Need to be lock-free and fast
- Client sends write to one coordinator node in Cassandra cluster
- Coordinator may be per-key, or per-client, or per-query
- Coordinator uses Partitioner to send query to all replica nodes responsible for key
- When
replicas respond, coordinator returns an acknowledgement to the client = any one, majority, all (consistency spectrum)
Hinted Handoff
To ensure that writes are eventually written to all replicas
- If any replica is down, the coordinator writes to all other replicas, and keeps the write locally until down replica comes back up
- When all replicas are down, the Coordinator (front end) buffers writes (for up to a few hours)
Writes at Replica Node
When a replica node receives a write request:
- Log it in disk commit log (for failure recovery)
- Make changes to appropriate memtables
- Memtable = in-memory representation of multiple key-value pairs
- Cache that can be searched by key
- Write-back cache as opposed to write-through
- Later, when memtable is full or old, flush to disk. The disk stores:
- Data file: an SSTable (Sorted String Table) - list of key-value pairs sorted by key
- Index file: An SSTable of (key - position in data sstable) pairs
- and a #Bloom Filter (for efficient search)
Bloom Filter
A Bloom Filter is a probabilistic data structure that is based on hashing.
- Compact way of representing a set of items
- Checking for existence in set is cheap
- Some probability of false positives: an item not in set may check true as being in set
- No false negatives
How it works:
- On insert, set all hashed bits to 1
- On check-if-present, return true if all hashed bits are 1
Compaction
- Data updates accumulate over time and over multiple SSTables
- Need to be compacted
- The process of compaction merges SSTables, i.e., by merging updates for a key
- Run periodically and locally at each server
Deletes
Deletes don't delete the data right away
- Writes a tombstone for the key
- Eventually, when #Compaction encounters tombstone it will delete item
Reads
Coordinator contacts
- Coordinator sends read to replicas that have responded quickest in past
- When
replicas respond, coordinator returns the latest-timestamped value from among those
Coordinator also fetches value from other replicas
- Checks consistency in the background, initiating a Read Repair if any two values are different
- The mechanism seeks to eventually bring all replicas up to date
At a replica
- Read looks at Memtables first, and then SSTables
- A row may be slit across multiple SSTables
reads need to touch multiple SSTables read slower than writes
Cross-DC Coordination
- Replicas may span multiple Data Centers.
- Per-DC coordinator elected to coordinate with other DCs.
- Election done via Zookeeper which runs a Bully algorithm variant.
Membership
- Any server in cluster could be the leader
- So every server needs to maintain a list of all the other servers that are currently in the cluster
- List needs to be updated automatically as servers join, leave, and fail
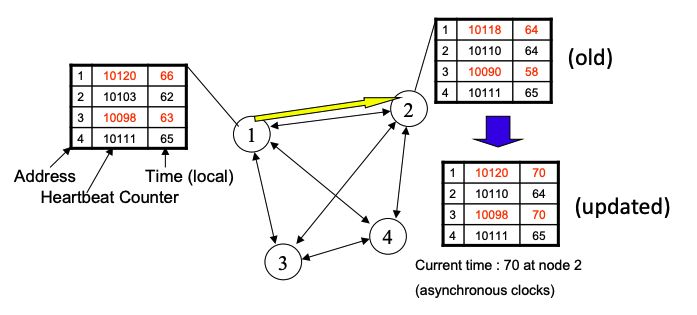
Cluster Membership
- Cassandra uses gossip-based cluster membership
- Nodes periodically gossip their membership list
- On receipt, the local membership list is updated, as shown
Consistency
Consistency Spectrum
Cassandra offers Eventual Consistency: if writes to a key stop, all replicas of key will converge.

Consistency Level
Client is allowed to choose a consistency level for each operation (read/write)
- ANY: any server (may not be replica)
- Fastest: coordinator caches write and replies quickly to client
- ALL: all replicas
- Ensures strong consistency, but slowest
- ONE: at least one replica
- Faster than ALL
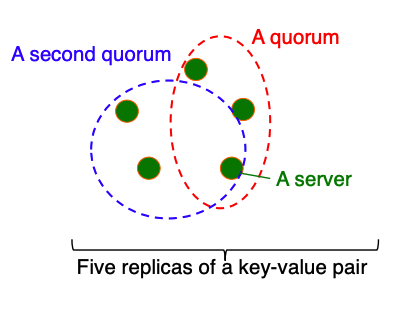
- QUORUM: quorum across all replicas in all data centers (DC)
- Faster than ALL, but still ensure strong consistency
- Any two quorums intersect
- Client 1 does a write in red quorum
- Then client 2 does read in blue quorum
- At least one server in blue quorum returns latest write
- EACH_QUORUM: quorum in every DC
- Lets each DC do its own quorum (not supported for reads)
- LOCAL_QUORUM: quorum in coordinator’s DC
- Faster: only waits for quorum in first DC client contacts
Quorum Details
Read Quorums
- Client specifies
total number of replicas of that key) = read consistency level
- Coordinator waits for
replicas to respond before sending result to client - In background, coordinator checks for consistency of remaining
replicas, and initiates read repair if needed
Write Quorums
- Client specifies
= write consistency level
- Client writes new value to
replicas and returns when it hears back from all
Necessary Conditions for consistency
- Write and read intersect at a replica. Read returns latest write.
- Two conflicting writes on a data item don't occur at the same time.
Values selected based on application
: great for read-heavy workloads : great for write-heavy workloads with no conflicting writes : great for write-heavy workloads with potential for write conflicts : very few writes and reads / high availability requirement
Eventual Consistency
Sources of inconsistency:
- Quorum condition not satisfied
and are chosen as such - when write returns before W replicas respond
- Sloppy quorum: when value stored elsewhere if intended replica is down, and later moved to the intended replica when it is up again
- When local quorum is chosen instead of global quorum
Hinted-handoff and read repair help in achieving eventual consistency
- If all writes (to a key) stop, then all its values (replicas) will converge eventually
- May still return stale values to clients (e.g., if many back-to-back writes)
- But works well when there a few periods of low writes – system converges quickly